
| < 前の記事 | | | Web講座TOP | | | 次の記事 > |
初心者向け Python講座 - 第5回「リストと文字列 ~ 前編」
投稿者:3G 大毛
これまでにint型、float型、bool型などのデータ型を学んできました。今回は新たなデータ型のなかまとして、リストと文字列を学んでいきます。
「リスト」とはいくつかのデータを並べて1つにまとめたデータのことで、Pythonではlist型と言います。Pythonのリストは実体としては「ルーズリーフ」と考えましょう。各ページにはデータの保管場所の情報(アドレスと言います)が1つ書かれています。ページの番号を指定すると、そこに書いてあるアドレスからたどってデータを取得することができます。ルーズリーフですから最後にページを追加したり、途中のページを別のものに差し替えたりすることができます。

「文字列」についてはあらためて説明する必要はないかもしれませんが、その名の通り文字を並べたデータのことで、Pythonではstr型と言います。strは文字列を意味するstringの略です。リストと文字列は似ている部分があり、文字列を文字のリストと考えることもできます。ただ、str型はルーズリーフのような高機能なものではなく、ただの「ノート」なのでページの追加や差し替えはできませんし、各ページには文字の保管場所ではなく文字自体が1つだけ書かれています。

★ プログラミング中級者以上を目指している皆さんへ ★ (※クリックして展開して下さい)
「可変型と不変型(mutable型とimmutable型)」
list型のように途中でデータを変更することができるデータ型を可変型(mutable型)といい、str型のように1回作ったら変更できないデータ型を不変型(immutable型)と言います。前回までに出てきた型(int, float, bool)はすべて不変型です。
1回作ったら変更できないということは、変更が必要になるたびに一から作り直さないといけないということですから、不変型はなんて不便なんだろうと思うかもしれません。しかし、プログラマがコードを書く上で可変型と不変型とでは書き方こそ違うものの、書く手間がすごく増えるというわけではありません。データの管理は基本的にPythonが行うのでプログラマはあまり関わらなくていいからです。可変型のデータを修正するときはメソッド等を用いた「属性や要素への代入」といった作業になりますが、不変型のデータを修正するときは関数等を用いた「再バインド」という作業になるという違いだけです。(ただし、不変型の方が便利な関数やメソッドの用意が少ないから不便だ、ということは確かにあります・・・。)
可変型と不変型はプログラマの利便性のためというよりは、使い分けることによって動作の速いプログラムを作るために用意されています。大まかに言って、コピーより修正の方が多いデータは可変型の方が有利で、修正よりコピーの方が多いデータは不変型の方が有利です。不変型のコピーは名札を増やすだけなのですぐにできますが、修正するのはデータを本当にコピーするのと同じくらいの手間です。可変型の修正はデータの一部分を変えるだけなのですぐにできますが、コピーするのは本当にコピーしないといけません。(可変型に複数の名札をつけるのはよくありません。「気づかないうちにデータが書き換えられていた」ということが起こるからです。)
なお後で紹介しますが、Pythonにはリストとほぼ同等の機能を持った不変型の「タプル」というデータ型が用意されています。Pythonプログラマはこのどちらを使うか、選択の余地が与えられているわけです。
リスト
今、変数 a, b, c がそれぞれ何らかのデータを表しているとしましょう。この3つをまとめて1つのデータとして扱えると便利なことがあります。それにはリストを使ってこのように書きます:
[a,b,c]
リストの作成
実際にリストを作ってみましょう。好きに選んだデータ3つをまとめたリストAを作り、AのデータとAの型を表示してみてください:
A=[1, 2.34, False] print(A) print(type(A))

3つのデータ「1」「2.34」「False」をまとめたリスト「A」が作成されました。型はlist型になっています。元の3つのデータのことを、Aの「要素」と言います。ところで最初の方で、Pythonのリストはルーズリーフだと言いました。リストをルーズリーフと考えるなら要素は「ページ」のことです。
Pythonに限らずプログラミングのリストはふつう、要素を0番から数えます。つまりAの0番目の要素は「1」、Aの1番目の要素は「2.34」、Aの2番目の要素は「False」となります。リストはルーズリーフとしては0ページ目から始まるわけです。
要素の番号、つまりページ番号のことは「インデックス」と呼びます。
要素の読み取り
リストから要素のデータを読み取るにはインデックスを指定します。いま、変数 A はリスト [0,1,2,3] を表すとしましょう。例えば、Aの2番目の要素は ”A[2]” と書いて読み取ります:
A=[0,1,2,3] A[2]

Aの2番目の要素が「2」であることが確認できました。
要素の差し替え
ルーズリーフは途中のページをあとから差し替えることができます。リストAの”1ページ目”のデータを「-10」に差し替えるには ”A[1] = -10” と書きます:
A=[0,1,2,3] A[1]=-10 print(A)

Aの1番目の要素が「1」から「-10」へ変わりました。この作業を「Aの1番目の要素に-10を代入する」と言います。
(注:この文は変数のバインドと似ていますが、バインドの時とは違い実際にデータ(=ルーズリーフの内容)が書き変わっているので「代入」と言います。ここで、ルーズリーフの内容というのは「-10」というデータ自体ではなく、「-10」というデータのアドレスであることに注意します。)
要素を最後に追加する
リストの最後に要素を追加するにはappendメソッドを使います。メソッドとはそれぞれのデータ型に備わっている関数のことです。メソッドを使うときはその前にドット「.」をつけます。
A=[0,1,2,3] A.append(-5.6e-7) print(A)

Aの最後に「-5.6e-7」が追加されました。
要素を挿入する
リストの途中に要素を挿入するにはinsertメソッドを使います。例えば、データ「100」がAの新しい”1ページ目”になるように差し込むには「A.insert(1,100)」と書きます:
A=[0,1,2,3] A.insert(1,100) print(A)

データ「100」が、Aの新しい1番目の要素になるように差し込まれました。
※ 上のコード例で、もしもinsert関数に4以上のインデックスを与えると、append関数で最後に追加するのと同じことになります。
要素を削除する
リストの要素を1つ削除して前につめるにはdel文を使います。delとは削除するという意味の動詞deleteの略です。例えば、Aの”0ページ目”を削除するには次のように書きます:
A=[0,1,2,3] del A[0] print(A)

Aの最初の要素が削除されました。(注:ルーズリーフのページが削除されるだけで、アドレスの先にあるデータ本体が削除されるわけではありません。)
リストの長さの取得
リストが持っている要素の数のことを「長さ」や「サイズ」と言います。リストの長さを取得するにはlen関数を使います。lenとは長さを意味するlengthの略です。
A=[0,1,2,3] len(A)

Aの長さは4、つまりAの要素は全部で4つであることが確認できました。
空のリスト
何も要素がないリスト、つまり長さが0のリストを「空のリスト」と言います。空のリストは [ ] と書けば作れます:
A=[] print(A) len(A)

空のリストは意外とよく使います。
リストの結合
2つ以上のリストをつなぎ合わせて、新しいリストを作ることができます。リストAとリストBをつなぎ合わせるには「A+B」と足し算のように書けばOKです:
[0,1,2,3]+[4,5,6]+[7]

リストの繰り返し
1つのリストを繰り返して、新しいリストを作ることができます。リストAを10回繰り返したリストを作りたいときは掛け算のように「A*10」と書きます:
[0,1]*10

文字列
文字列は文字を要素とするリストのようなものですから、リストと同じようにインデックスを指定して文字を取得したり、長さを取得したり、結合や繰り返しの操作ができます。ただし、高機能なルーズリーフであるリストとは違い、文字列はノートなので一度作ったら変更できません。ですから、リストのようにページの追加や削除をする機能は用意されていません。
それでは、文字列を変更したいときはどうするのか?ということですが、それは次回ご説明します。(スライスと結合を使って新しい文字列として作ります。)
文字列の作成
第3回でも出てきましたが、文字列はシングルクォート「'」かダブルクォート「"」で囲んで作ります。どちらを使っても同じです。また文字列で使う文字は日本語でもOKです。好きな言葉の文字列を2通りの方法で作ってみましょう:
A = 'あいうえお' print(A) print(type(A))

B = "あいうえお" print(B) print(type(B))

どちらも文字列が作成され、str型であることが分かりました。(なお、この場合AとBは本当に同じデータをバインドしています。)
改行の入った文字列
第3回ではprint関数で改行されないようにする方法を勉強しました。今度は逆に改行を含む文字列を作ってみます。 改行するには「\」を使って「\n」と書きます。ただし、日本語のキーボードを使っている人は「 \ 」を「¥」と打ってください。(なお、日本語の設定でColabを使っている人は「 \ 」が自動的に「¥」に変換されて表示されます。)
好きな言葉を1文字ずつ改行して縦書きにしてみましょう:
C = 'あ\nい\nう\nえ\nお' print(C)

引用符の入った文字列
「 I can't say "No." 」のように引用符(シングルクォート「'」やダブルクォート「"」のこと)が入った文字列を作ろうとするときは注意が必要です。試しに「'」や「"」で囲ってみましょう:
'I can't say "No."'
"I can't say "No.""
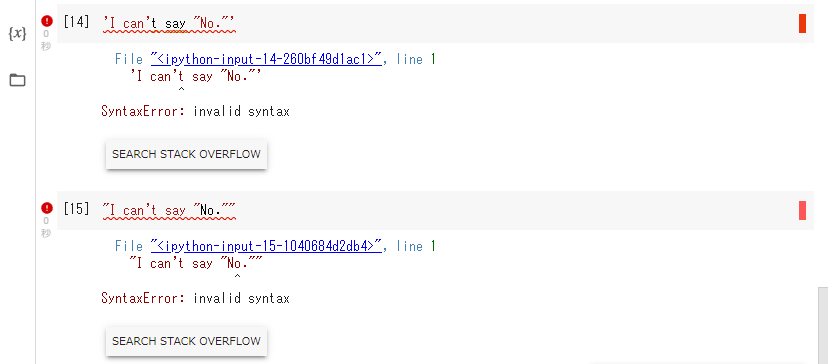
どちらもエラーになってしまいます。
引用符を含む文字列を作るときは引用符の前に「\」を入れてください:
A = 'I can\'t say \"No.\"' B = "I can\'t say \"No.\"" print(A) print(B)

引用符を含む文字列が問題なく作成されました。
実は、どちらかの引用符しか現れない場合は、もう一方の引用符で囲めば問題ありません:
A = 'James, while John had had "had," had had "had had."' B = "You're the best." print(A) print(B)

文字列Aの方はダブルクォート「"」しか現れないので、シングルクォート「'」で囲めばOKです。
文字列Bの方はシングルクォート「'」しか現れないので、ダブルクォート「"」で囲めばOKです。
※ ちなみにAは有名な英文でWikipediaにも項目があります。訳すと「Johnは過去形の"had"を使ったのに対して、Jamesは過去完了形の"had had"を使った。」です。
文字列の長さの取得
文字列の長さもlen関数で取得できます。
len('ABCDEFGHIJKLMNOPQRSTUVWXYZ')
AからZまで順に並べた文字列の長さが26になりました。アルファベットは全部で26文字あるのでこれは正しいです。
要素の読み取り
文字列の中の1文字を読み取るには、リストと時と同じくインデックスを指定します:
A='_ABCDEFGHIJKLMNOPQRSTUVWXYZ' c = A[26] print(c) type(c)

文字列Aの26番目の文字が 'Z' であることが確認できました。(注:先頭に「 _ 」をつけたので文字列Aの長さは27です。)
Pythonには”文字型”というデータ型はありません。文字は、長さ1の文字列と考えます。ですから、A[26]はstr型になります。
空文字列
長さが0の文字列を「空文字列」と言います。引用符を2回連続で書いて作ります。どちらの引用符で書いてもOKです。
A='' print(A) len(A)

B="" print(B) len(B)

空文字列をprint関数で出力すると改行だけされます。
文字列の結合
2つ以上の文字列をつなぎ合わせて、新しい文字列を作ることができます:
'Hello,' + ' ' + 'world!'

※ プログラミング言語の初心者向けの本では、最初に 'Hello, world!' と出力するのが習わしになっています。
文字列の繰り返し
1つの文字列を繰り返して、新しい文字列を作ることができます:
"Buffalo " * 8

※ ちなみにこれは有名な英文でWikipediaにも項目があります。訳すと「バッファロー市のバッファロー達にいじめられているバッファロー市のバッファロー達がバッファロー市のバッファロー達をいじめている」です。
リストと文字列の前編はここでおしまいです。たくさんの項目が出てきましたが、すべてを覚えようとしなくて大丈夫です。使っていくうちに自然と覚えていきます。次回は後編に続きます。リストはプログラミングの主役のデータ型ですのでがんばりましょう。
| < 前の記事 | | | Web講座TOP | | | 次の記事 > |