
| < 前の記事 | | | Web講座TOP | | | 次の記事 > |
初心者向け Python講座 - 第6回「リストと文字列 ~ 後編」
投稿者:3G 大毛
今回はリストと文字列の続きということで、主に「スライス」を勉強します。スライスというのは「スライス・チーズ」と言うときと同じで「薄く切る」という意味です。スライスを使うとリストや文字列の一部分を切り取ることができます。
スライスを使うには始めのインデックス(始点と言うことにします)と終わりのインデックス(終点と言うことにします)を指定します。もし始点が m で終点が n なら、スライスは [m:n] と書いて、インデックスが「m 以上 n 未満」の部分を表します。よく間違いやすいのですが「m 以上 n 以下」ではないので注意しましょう!
例えば、長さが4のリスト A=[4,5,6,7] があるとします。いま、Aの1番目から2番目までの要素をまとめて取り出したいとします。このとき、スライスを使って A[1:3] と書けば目的のリスト [5,6] が得られます。(※要素は0番から数えるのでした)
「1から2」が欲しいのに「1から3」と書かないといけないので少しややこしいですね。これはこのように理解してください:いま、4cmまで測れる定規があります。この定規の1cm台から2cm台の部分を黒く塗りつぶしてください。何cmから何cmまで塗ればよいでしょうか? ・・・・・・ 答えは1cmから3cmまでです!

◆ コラム「AIで使う巨大なリスト」 ◆ (※クリックして展開して下さい)
スライスの終点が「未満」を表すというのはPythonに限らずよくあることです。おそらく、A[m:m]と書けば空のリストができて便利だからだと思います(注:m 以上 m 未満の数はないので空になります)。しかし、Pythonを使っているとそれ以外に実用的な面でメリットがあると気づきました。次のようなことです。
機械学習を使って AI(人工知能)を訓練させるときはビッグデータと言って大量のデータを与えて計算させることがあります。その時に使われるのが何万、何十万といった長さの巨大なリストです。そのリストから例えば、0番目から2万個のデータを読み取りたいときは [0:20000] とすればいいのですが、もしスライスの終点が「未満」ではなく「以下」を表すとしたら [0:19999] と書かないといけません。「未満」の方が少しきれいに書けますね。
スライス
スライスを使うと、リストや文字列の中のいくつかの要素をまとめて読み書きすることができます。
要素をまとめて読み取る
いま、A=[4,5,6,7]とします。リストAの1番目から2番目までの要素をまとめて読み取ってみましょう:
A=[4,5,6,7] A[1:3]

Aの1番目から2番目までの要素が新たなリストとして出力されました。
文字列の場合でもできます。いま、A='PPAP'とします。Aの1番目から2番目までの文字をまとめて読み取ってみましょう:
A='PPAP' A[1:3]

Aの1番目から2番目までの文字からなる新たな文字列'PA'が出力されました。
要素をまとめて差し替える(リストのみ)
スライスにリストを代入することで、リストの途中部分を別のリストに差し替えることができます。
Aの1番目から2番目の部分を別のリスト [10,20,30] に差し替えてみます:
A=[4,5,6,7] A[1:3]=[10,20,30] print(A)

[5,6]の部分が[10,20,30]に変わり、全体の長さも1増えました。この操作は非常に強力で、実は差し替えだけでなく挿入や削除もできてしまいます。その前に「空のスライス」について説明します。
空のスライス
A[2:2]と書いたとき、これは何を表すでしょうか?・・・2以上2未満の数というのはありません。スライスの始点と終点が同じか、あるいはA[3:2]のように逆になっている場合は、条件に合致するインデックスはありませんので、空のリストまたは文字列を表すことになります。このようなスライスを「空のスライス」と言うことにしましょう。
print(A[2:2]) print(A[3:2])

要素をまとめて挿入する(リストのみ)
Aの2番目の位置に別のリストを挿入したいときは空のスライスA[2:2]に代入すればOKです。空のリストを別のリストに差し替えるわけですから、挿入と同じことになります。
A=[4,5,6,7] A[2:2]=[10, 20, 30] print(A)

Aの最後に別のリストを追加したいときは、Aの長さがmのときは、空のスライスA[m:m]に代入すればOKです。
A=[4,5,6,7] m=len(A) A[m:m]=[-1,-2] print(A)

Aに別のリスト[-1,-2]が追加されました。今回、mは4なので、A[4:4]=[-1,-2]としても同じです。
要素をまとめて削除する(リストのみ)
今度は逆にスライスに空のリストを代入することによって、要素をまとめて削除することができます。Aの0番目から2番目の要素を削除するには次のようにします:
A=[4,5,6,7] A[0:3]=[] print(A)

複数の要素の削除はdel文を使ってもできます。
A=[4,5,6,7] del A[0:3] print(A)

始点と終点の省略
スライスの始点と終点は省略することができます。
始点を省略するとスライスはリスト・文字列の始めからとなります。始点を0としたのと同じです:
A=[4,5,6,7] A[:2]

終点を省略するとスライスはリスト・文字列の最後までとなります。終点を長さ以上の数としたのと同じです:
A=[4,5,6,7] A[1:]

始点と終点の両方を省略するとスライスは元のリスト・文字列と同じ内容になります。
A=[4,5,6,7] A[:]

Aと同じ内容のコピーが作成されました。(注:正確には、文字列の場合はコピーではなく元の文字列そのものになりますが、このことは気にしなくて問題ありません。)
文字列の編集
文字列にはリストのような編集機能が用意されていません。そのため文字列を編集するときはスライスと結合をうまく使って新たな文字列として作成する必要があります。
例えば、'PenPineappleApplePen'の'Apple'を'Peanut'に差し替えたいときはこのようにします:
A = 'PenPineappleApplePen' B = A[:12] + 'Peanut' + A[17:] print(B)

文字列の途中の部分を削除したり、別の文字列を挿入することも同じようにできます。
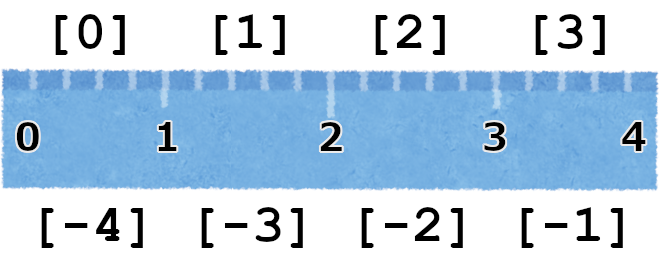
負のインデックス(中級者向け)
実はインデックスは負の数もとれます。リスト・文字列の最後の要素はインデックス「-1」、最後から2番目の要素はインデックス「-2」、・・・というふうに言うことができます。
A=[4,5,6,7] print(A[-1]) print(A[-2]) print(A[-3]) print(A[-4])

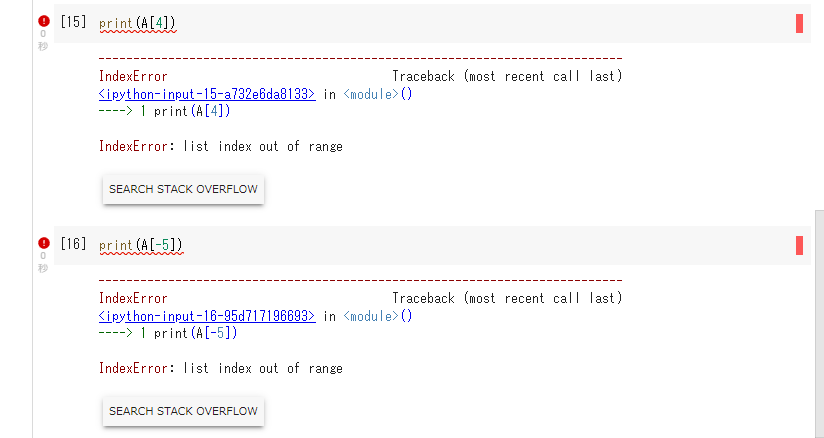
これ以外のインデックスを指定するとエラーになってしまいます。
print(A[4]) print(A[-5])
ちなみにスライスの場合はインデックスとしてどんな整数を指定してもエラーにはなりません。
print(A[5:5]) print(A[-5:5]) print(A[5:-5]) print(A[-5:-5])

リストをコピーするときの注意点
リストをコピーするときには注意が必要です。次の例を見てください:
A=[0,1,2,3,4] B=A print(A) print(B) A[2]=5 print(A) print(B)
まず、Aを[0,1,2,3,4]というリストにしてから、BにAを”コピー”します。現時点でA, Bともリスト[0,1,2,3,4]を表していることをprint関数で確認します。次にAの2番目の要素を「5」に変更します。そのあとA, Bの内容をprint関数で確認すると、いったい結果はどうなるでしょうか?

Bを変更したつもりはないのに、Aと同じように書き換わってしまっています!どうしてでしょうか?
その答えは「B=Aのところでデータのコピーが行われていないから」です。実際には「名札Bを名札Aと同じ場所に貼り付けた」が正解です。リストBはリストAの単なる別名にすぎません。ですから、Aのデータを変更するとBのデータも変更されてしまうのです。
リストをコピーするには、1つは、始点と終点を省略したスライスを使う方法があります:
A=[0,1,2,3,4] B=A[:] print(A) print(B) A[2]=5 print(A) print(B)

Bが変更されなくなりました。この書き方だとしっくり来ないな、という人は copy 関数を使って次のように書くこともできます:
A=[0,1,2,3,4] B=A.copy() print(A) print(B) A[2]=5 print(A) print(B)
後から読み返したときに何をやっているのかが分かりやすいので、こちらの方がおすすめです。

◆ 「浅いコピーと深いコピー」(中級者向け) ◆ (※クリックして展開して下さい)
リストをルーズリーフと考えた場合、各ページにはデータのアドレスが書かれていたのでした。A[:] や A.copy() はルーズリーフのコピーになるので、アドレスの先にあるデータ自体はコピーされません。そのためこれらは「浅いコピー(shallow copy)」と呼ばれます。これに対して、要素のデータも、(その要素の要素のデータも、・・・)すべてコピーする場合は「深いコピー(deep copy)」と呼ばれます。
深いコピーは標準ライブラリのcopyモジュールにあるdeepcopy関数を使うとできます。copyモジュールを使うには、使う前に「import copy」という文を書く必要があります。
次の例で、浅いコピーと深いコピーの違いを見てみましょう:
import copy A = [1, [2,3], 4, [5,[6,7],8], 9] B = A.copy() C = copy.deepcopy(A) A[0] = 0 A[1][1] = 0 A[3][1][0] = 0 print(A) print(B) print(C)
A はリストを要素に持つリストです。A の浅いコピーを B とし、深いコピーを C とします。コピーした後に、A のいくつかの要素を変更するとそれぞれどうなるでしょうか?

浅いコピー B では、浅いレベルの変更(ここでは要素 A[0] の変更)は連動しませんが、深いレベルの変更(ここでは要素 A[1][1] と要素 A[3][1][0] の変更)は連動してしまうことが分かります。それに対して深いコピー C では、深いレベルの変更も影響を受けないことが分かります。
数や文字列のような不変型の要素だけからなる場合は「浅いコピー」で問題ありませんが、リストのような可変型の要素を持つ場合は「深いコピー」をした方がよいというわけです。
リスト・文字列の比較
等しい(==)・等しくない(!=)
リストや文字列も数と同じように、「==」や「!=」を使って等しいかどうかを判定できます:
print([0,1,2]==[0,1,2])
print([0,1,2]!=[0,1])
print('cat'=="cat")
print('Cat'!='cat')
長さが同じで、すべての要素も等しいとき、等しくなります。文字列の比較は大文字・小文字も区別するので注意します。
より小さい(<)・以下(<=)(上級者向け)
文字列も数と同じように、比較演算子の「<」や「<=」が使えます。どのような意味になるかというと、辞書で出てくる順番に関して早いか遅いかを判定します。この比較方法はリストにも応用することができます。詳しく知りたい人は下のコラムをクリックしてください。難しい内容ではありませんが、使用頻度から考えて上級者向けとしました。
◆ 「辞書式順序」(上級者向け) ◆ (※クリックして展開して下さい)
国語や英語の辞書に出てくる言葉の順序を辞書式順序といいます。Pythonは文字列の比較にこの順序を使います。例えば、英語の辞書で「start」は「stop」の前に出てくるので、「'start' < 'stop'」は「True」になります。
'start' < 'stop'

記号などはどうなるのかというと、文字コードの順番で判断します(PythonではUnicodeを使います)。
'1+1' <= '1-1'

なお、文字コードはord関数で取得できます。
print(ord('+'))
print(ord('-'))
リストの場合も同じように考えます。例えば、「 [0,1,2,3] < [0,1,3] 」は「True」になります。インデックス毎に要素を比較していき、同じだった場合は判断を次のインデックスに持ち越すというわけです。(注:どちらかの要素が存在しなければ、存在しないほうが小さいです。両方存在しなければリスト全体として等しいということになります。)
[0,1,2,3] < [0,1,3]

あるインデックスの要素が例えば、int型とstr型であった場合などは比較不能ということでエラーになります。
[0,1,2] <= [0,1,'a']


お疲れさまでした!ここまで読んだあなたはPythonのデータ型についてひと通り勉強できたと言って良いでしょう。というのも、確かにまだ勉強していないことはたくさんありますが、今まで習ったことを組み合わせて工夫すればできないことはあまりないからです。ただし、一つだけ困ることがあるとすれば他の人や上級者が書いたコードを読むときです。時間に余裕のある人や中級者以上を目指したい人は次回の第7回へ進んでください。それ以外の人は次回は飛ばして第8回に進んでください。
| < 前の記事 | | | Web講座TOP | | | 次の記事 > |